 GitBucket
GitBucket
Bonnes pratiques
- Bonnes pratiques
Développement
Avant de programmer
Cloner le dépôt
Il faut avoir cloné le dépôt sur sa machine:
git clone ssh://git@gitbucket.inist.fr:22222/tdm/web-services.git
Cette étape n'est nécessaire qu'une seule fois.
Se mettre dans le répertoire web-services
On réutilise toujours le même répertoire de travail (normalement nommé par la commande précédente web-services).
Synchronisation
Avant de commencer la création d'un nouveau service, on rapatrie les dernières modification du dépôt (à partir de la racine, c'est-à-dire le répertoire web-services):
git pull
Nouvelle branche
En fonction de ce que vous voulez faire, créez une branche:
create-serviceoù vous remplacezservicepar le nom du service que vous envisagez de créerfix-serviceoù vous remplacezservicepar le nom du service que vous envisagez de corrigerimprove-serviceoù vous remplacezservicepar le nom du service que vous envisagez d'améliorer
Exemples de noms de service (qui correspond au nom de l'instance suivi de la route du service à créer):
terms-extraction-v1-teeft-de,affiliations-tools-v1-ror
Le nom de la branche doit rester compréhensible.
Techniquement, le nom de la branche n'est pas très important, mais il l'est pour l'équipe (par exemple, pour savoir ce qui est déployé en vi)
git checkout master # on s'assure qu'on est sur la branche principale git checkout -b create-service # on crée la branche et on s'y déplace
Pull Request
Créez une pull request où vous pourrez documenter plus largement que dans les messages de commit ce que vous faites.
Ça permet également d'avoir une discussion portant sur la modification en cours.
Ça permettra aussi de montrer votre code à quelqu'un d'autre avant de le valider.
La pull request se crée à partir de la branche que vous avez créée, mais elle doit au moins contenir un commit.
Sur le menu Pull requests de GitBucket cliquez sur New pull request (en haut à droite de la page).
Si vous ne voyez pas le bouton, connectez-vous à GitBucket.

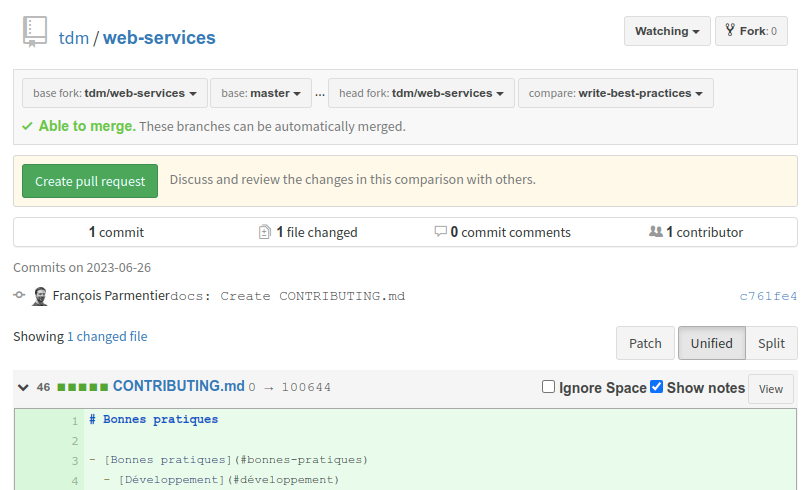
Par défaut, on tombe sur une page comparant la branche master à... la branche master.

Comme vous avez déjà poussé votre branche, vous pouvez la sélectionner (à droite):
Il est important de donner un titre et une description parlante à votre pull request, c'est ce qui permettra de la retrouver facilement.
En général, le titre est lié au nom de la branche, si on a été bien inspiré en créant la branche.

Comme la pull request est dédié à la communication entre nous, on peut y écrire en français (dans un projet open source classique, on préfère utiliser l'anglais).

Il ne reste plus qu'à continuer à travailler dans la branche de la pull request, en n'oubliant pas de pousser régulièrement les commits sur le dépôt.
git push
💡 Note: Si vous collaborez avec une autre personne dans la branche de la pull request, n'oubliez pas de faire un
git pull, avant de modifier vos fichiers.
L'utilisation de VSCode peut aider, il vérifie régulièrement si une synchronisation est nécessaire.
Nouvelle instance ?
Vérifier si une instance existante serait réutilisable
Les instances rassemblent des services:
- dans le même thème
- partageant des dépendences techniques (type de worker)
Par exemple, affiliations-tools regroupe addresses, netscity et rnsr, qui travaillent tous les affiliations (même thème).
Les biblio-tools, partagent certes un même thème, mais ne dépendent que de ezs, d'où leur utilisation de lodex-workers, le plus léger des workers (python n'y est pas installé, ni aucun paquet comme libpostal).
Moins il y a d'instances, moins le serveur de production a besoin d'être puissant (et c'est meilleur pour la planète).
Dans la mesure du possible, essayez donc d'ajouter vos services dans des instances existantes (les instances ont chacun un répertoire à la racine du dépôt, et respectent la convention de nommage).
Si aucune instance n'est réutilisable
Lorsqu'on n'a pas d'autre choix que de créer une instance, il faut:
- déterminer un nom d'instance en suivant les conventions de nommage (un tiret au milieu, ...)
- création du répertoire de l'instance (les deux premières parties du nom de l'instance, séparées par un tiret)
- création de la route v1/... en fonction des répertoires et du fichier
.ini. - création de
swagger.json, contenant le numéro de version de l'instance (0.0.0) - création de
examples.http
swagger.json de base
Le champ info.version doit contenir 0.0.0, car il sera modifié lors de la création de version.
On peut créer un ou plusieurs tags à affecter à chaque service.
Il leur faut un name parlant, court et une description un peu plus longue (mais pas trop). Ces deux champs apparaissent dans l'OpenAPI.
On ajoute aussi un externalDocs qui pointe sur le README de l'instance. Lui aussi sera présent dans l'OpenAPI.
{
"info": {
"version": "0.0.0"
},
"tags": [
{
"name": "terms-extraction",
"description": "Extraction de termes",
"externalDocs": {
"description": "Plus de documentation",
"url": "https://gitbucket.inist.fr/tdm/web-services/tree/master/terms-extraction"
}
}
]
}

Création du .ini: v1/service.ini
Le chemin du .ini détermine la route du service.
Par exemple, le fichier terms-extraction/v1/teeft/en.ini donnera l'URL https://terms-extraction.services.inist.fr/v1/teeft/en, dont la route est v1/teeft/en.
Il faut donc bien réfléchir au chemin du fichier.
De même, le mieux est d'avoir une route courte, plus facile à retenir, à taper sans faute de frappe, ...
Il est donc inutile de créer le .ini dans un chemin dont une partie n'aurait pas de signification (par exemple: terms-extraction/v1/teeft/en/expand.ini, ici la partie /expand n'a aucune utilité).
On n'a besoin de répertoire que quand il faut y placer au moins deux services (deux .ini) différents.
Métadonnées de base
Les métadonnées du service sont écrites dans le fichier .ini.
C'est le serveur ezs qui les interprète et les utilise pour la route du service, ou pour les intégrer dans le swagger qui sera utilisé sur openapi.services.inist.fr.
N'hésitez pas à ajouter des commentaires dans le fichier.
Il suffit de commencer une ligne par # ou par ;.
mimeType = application/json
La première ligne à ajouter est:
mimeType = application/json
post.operationId
Chaque service doit avoir un identifiant unique (ça permet d'avoir des liens uniques dans OpenAPI, et de nommer les requêtes dans examples.http).
Lorsque l'identifiant n'est pas unique, le lien vers l'OpenAPI qui est fourni dans ObjectTDM est cassé !
La convention pour construire cet identifiant est de partir du chemin du fichier .ini, de supprimer le .ini, et de remplacer chaque / par un -; il faut aussi le commencer par la méthode HTTP utilisée (pour les services web, c'est post sauf exception).
Ainsi, terms-extraction/v1/teeft/en.ini se traduit en post-v1-teeft-en.
post.operationId = post-v1-teeft-en
post.summary
Description courte de la route, qui apparaît à droite de la route avant d'être dépliée dans OpenAPI.

post.description
Description longue de la route, qui apparaît une fois que la route a été dépliée dans OpenAPI.

On peut y employer MarkDown:
post.description = Traitement qui prend un objet JSON content un `id` et une `value` (contenant une année de publication, `year`, et une adresse `address`) et renvoie un `id` et une `value` (un tableau d'identifiants RNSR).
Remarque: la colorisation syntaxique des éditeurs pour les
.iniest parfois abusée par le contenu des métadonnées (par exemple, dans ce cas, une apostrophe seule est considérée comme un début de chaîne de caractères, non fermée).
Il n'y a pas à s'inquiéter, puisque cette syntaxe est bien comprise par le serveur ezs, qui la transforme en un JSON compréhensible par Swagger (le moteur d'OpenAPI).
post.tags
Les tags permettent de ranger les routes par sujet dans la page de présentation de l'instance sur OpenAPI.

Le champ post.tags est un tableau, il nécessite donc d'utiliser un indice:
post.tags.0 = rnsr
On peut apposer plusieurs tags à une route, mais il reste encore à harmoniser les manières de faire pour tous les services web.
Pour fonctionner, un tag doit être déclaré dans le fichier swagger.json qui se trouve à la racine de l'instance.
Ce fichier ne contient que les informations à ajouter au fichier généré automatiquement par le serveur ezs (et qui est exposé à sa racine).
C'est le champ tags.*.name du swagger.json qui doit correspondre au champ post.tags.n. Il sert d'identifiant.
Exemple:
{
"info": {
"version": "1.1.2"
},
"tags": [
{
"name": "rnsr",
"description": "RNSR",
"externalDocs": {
"description": "Plus de documentation",
"url": "https://gitbucket.inist.fr/tdm/web-services/tree/master/affiliations-tools#v1%2frnsr%2fcsv"
}
}, {
"name": "adresses",
"description": "Adresses",
"externalDocs": {
"description": "Plus de documentation",
"url": "https://gitbucket.inist.fr/tdm/web-services/tree/master/affiliations-tools#v1%2faddresses%2fparse"
}
}
]
}
À CONTINUER... Avec les métadonnées de base: post.responses.default.description, responses.default.content.application/json.schema.$ref, post.requestBody.required/content ...
validation swagger Modèle de base en ezs pur / avec python. À COMPLÉTER
Python
Relation .ini . .py Exemple de .ini et structure de base du .py.
version de python
Utiliser un environnement virtuel
Il faut avoir un environnement virtuel (nommé .venv) à la racine de l'instance.
Le nommer .venv permet à VSCode, par exemple, de l'activer automatiquement.
S'il n'existe pas encore, il faut le créer (attention: depuis la racine de l'instance):
python3 -m venv .venv
Une fois qu'il existe, il ne faut pas oublier de l'activer avant de tester ses programmes:
source .venv/bin/activate
requirements.txt
Le fichier requirements.txt, placé à la racine de l'instance, est utilisé au lancement de l'instance pour installer les paquets python nécessaires.
Il est donc primordial qu'il contienne les noms des paquets à installer, sous peine d'avoir des services déficients.
Pour n'avoir aucune surprise de comportement, il faut aussi y préciser la version de chaque paquet (une version majeure plus récente que celle utilisée pendant le développement peut planter le programme).
Pour éviter que le service soit trop lent à démarrer, il ne faut installer que les paquets nécessaires.
⚠ Il est possible que d'autres services de la même instance soient écrits en python, et aient déjà ajouté leurs dépendances dans le fichier
requirements.txt.
C'est pourquoi il est nécessaire, avant toute chose, d'installer ces éventuels paquets (évidemment, après avoir activé l'environnement virtuel):pip install -r requirements.txt⚠ Il faut être conscient qu'une instance peut héberger plusieurs services différents, potentiellement écrits par d'autres personnes, à des moments différents.
Cela peut impliquer plusieurs choses:
- conflit de versions d'un même paquet
- rendre un service existant inopérant (en supprimant un de ses dépendances)
Une bonne manière de savoir quels sont exactement les paquets à mettre dans requirements.txt, et de lancer pip freeze, qui fournit les noms et les numéros des paquets PIP à ajouter tels quels dans le fichier.
$ pip freeze joblib==1.3.1 numpy==1.24.4 scikit-learn==1.3.0 scipy==1.10.1 threadpoolctl==3.2.0
programme python
Nommer le programme python comme le .ini (mais c'est le .ini qui détermine la route du service).
Tester localement
node
Tester localement
Documentation
paquets ezs
examples.http
Si le fichier n'existe pas, utiliser ce modèle pour l'entête:
# These examples can be used directly in VSCode, using REST Client extension # (humao.rest-client) or httpYac (anweber.vscode-httpyac) # To test locally, replace with #@host = http://localhost:31976 @host = https://instance-name.services.inist.fr #@host = http://instance-name.tdmservices.intra.inist.fr ###
Puis, ajouter au moins autant d'exemples de requêtes que de routes.
# @name v1Cnrsunit
# @description Informations sur une adresse cnrs
POST {{host}}/v1/cnrsunit/cnrsunit?indent=true HTTP/1.1
Content-Type: application/json
[
{"id":1, "value":"université sciences et technologies bordeaux 1 institut national de physique nucléaire et de physique des particules du cnrs in2p3 umr5797"},
{"id":3,"value":"centre de recherches sur la géologie des matières premières minérales et énergétiques cregu université de lorraine ul umr7359 centre national de la recherche scientifique"},
{"id":4,"value":"umr_d161 institut de recherche pour le développement ird um34 aix marseille université amu umr7330 collège de france cdf institution institut national des sciences de l'univers insu cnrs umr7330 centre national de la recherche scientifique cnrs umr1410 institut national de recherche pour l'agriculture l'alimentation et l'environnement inrae centre européen de recherche et d'enseignement des géosciences de l'environnement cerege europôle méditerranéen de l'arbois"}
]
###
Le ### sur une ligne est un séparateur de requêtes.
La partie @name permet d'identifier la requête (utile à l'étape de génération des métadonnées d'exemple).
Ce fichier est un pivot pour:
- générer les métadonnées d'exemples pour OpenAPI
- créer des tests automatiques (à venir)
Il est donc très important.
Déploiement
Tester sur la vi
Déployer le service sur la vi
La version de la branche. Même configuration qu'en vp, sauf qu'on utilise le nom de la branche à la place du tag de la version future.
Tester le swagger
www-home
Si c'est une nouvelle instance, l'ajouter dans le index.html de www-home, qui sera openapi.services.inist.fr.
Code review
Merge vers master
Faire une version
Vérifier l'utilisation (grafana)
S'assurer, via le tableau de bord de Grafana, que l'instance en question n'est pas sollicitée.
Le but est de ne pas casser une série de requêtes en cours.

Déployer sur la vp
La version générée instance@version.
Utiliser les dépendances de la vi pour mettre à jour celles de la vp.

Cas d'une nouvelle instance
- publier l'instance dans
internal-proxyetinternal-monitoringviamake publishÀ COMPLÉTER - changer le
titledans la configuration À COMPLÉTER - créer un fichier
instance-conf.jsonà la racine du dépôt À COMPLÉTER
Pour la publication dans internal-proxy et internal-monitoring, il faut renseigner, dans le répertoire de l'instance, le fichier swagger.json puis lancer make publish sur ce répertoire.
Ex de swagger.json:
{
"info": {
"title": "ark-tools - Génération des identifiants ARK",
"summary": "Permet la génération d'identifiants ARK uniques et pérennes.",
"version": "1.0.0",
"termsOfService": "https://objectif-tdm.inist.fr/",
"contact": {
"name": "Inist-CNRS",
"url": "https://www.inist.fr/nous-contacter/"
}
},
"servers": [
{
"x-comment": "Will be automatically completed by the ezs server."
},
{
"url": "http://vptdmservices.intra.inist.fr:49194/",
"description": "Latest version for production",
"x-profil": "Standard"
}
],
"tags": [
{
"name": "ark-tools",
"description": "Génération des identifiants ARK",
"externalDocs": {
"description": "Plus de documentation",
"url": "https://gitbucket.inist.fr/tdm/web-services/tree/master/ark-tools"
}
}
]
}
Champs importants: dans servers, champ url.
Lancer avec:
make publish <nom du répertoire de l'instance>
Le login et le mot de passe du ezmaster hébergeant le reverse proxy seront demandés, seules les personnes ayant ces informations peuvent effectuer cette publication.
Après le déploiement
Lancer les tests de non-régression
Si on a seulement ajouté une ou plusieurs routes à une instance déjà en production, vérifier que les anciennes routes continuent à fournir les résultats attendus.
npx hurl <nom du répertoire de l'instances>/tests.hurl
Générer les tests
Cette section a pour objectif d'ajouter les nouvelles routes de l'instance, ou de créer le fichier de tests s'il n'existait pas encore.
Dans le répertoire racine du dépôt, lancer
make generate-examples-tests <nom du répertoire de l'instance>
Puis, vérifier qu'ils passent bien (puisqu'on vient de les générer, cela vérifie seulement que deux appels identiques ont les mêmes résultats).
npx hurl <nom du répertoire de l'instances>/tests.hurl
Ajouter les tests au dépôt
Évidemment, il ne faut pas oublier d'ajouter le fichier de tests au dépôt.
À ce stade, un mainteneur du dépôt peut le pousser directement dans la branche principale, sinon il faut refaire une Pull Request.
git add <nom du répertoire de l'instance>/tests.hurl git commit -m "test(instance): Add tests.hurl" git push
Vérifier que le swagger fonctionne
Si c'est une nouvelle instance, il se peut qu'elle n'apparaisse pas immédiatement dans openapi.services.inist.fr, car ce site est mise à jour automatiquement toutes les demi-heures (pendant les heures de bureau, les jours de semaine).
Une fois que https://openapi.services.inist.fr/ affiche les routes que vous venez de développer / corriger / documenter, utilisez le bouton Try it out sur cette/ces route/s:

Puis, le bouton Execute.

Le résultat doit correspondre à l'exemple (avec un code 200).

catalogues LODEX
Signaler dans le canal mattermost #TDM les nouvelles routes, pour qu'elles puissent être ajoutées au catalogue de LODEX.

Objectif TDM
Fiche du service
La fiche d'un service web doit avoir (le titre d'une section sera en style Titre 2):
- titre: le plus court et explicite possible
- sous-titre: la première phrase de la fiche fera office de description dans la prévisualisation présente sur la page d'accueil d'objectif TDM, il faut donc aller droit au but, pas besoin de construire une phrase. Si la phrase est trop longue, il est possible qu'on n'en voie que le début
- description: plus longue et détaillée que le sous-titre, décrit ce que fait le service web. Y compris les paramètres éventuels (
indentou autre). - image: idéalement, un usage de l'enrichissement dans LODEX
- algorithme: une section consacrée à la manière dont fonctionne le service (est-ce un apprentissage, une heuristique, ...)
- qualité: une section donnant une idée de la qualité du service (expérimental, avec des retours utilisateurs, avec une f-mesure, rappel, bruit, précision, ...). Ne s'applique pas de la même manière suivant les algorithmes. Donner une idée de la rapidité du service serait intéressant aussi (procédure à déterminer pour pouvoir comparer les services entre eux)
- corpus d'apprentissaga / test: sur quelles données s'appuient les tests et/ou l'apprentissage
- références: bibliographie + code source (liens) + éventuel URL variante (anglais/français par exemple)
Exemple de sous-titre trop long:

La catégorie à affecter à la fiche est Web-services, pas Blog/Webservices.

Blocs à remplir:
- URL Lodex: on y met l'URL du service
- Entrée: généralement un JSON, on utilise l'extension
Code Blockpour coloriser le code et garder les indentations (pour saisir les indentations, mieux vaut passer eTexteplutôt que de rester en modeVisuel). - Résultat: comme l'Entrée.
- Utiliser: lien vers l'OpenAPI
- Se documenter: lien vers l'article générique https://objectif-tdm.inist.fr/se-documenter/

Indexation:
Dans la mesure du possible, sélectionner:
- but
- tâche
- langue
Cela permettra aux visiteurs d'Objectif TDM de trouver plus facilement les services qui les intéressent (même si le fait de sélectionner certains de ces items ne change rien dans la prévisualisation de l'article, puisque c'est la page de recherche du WordPress qui est impactée).
Note: c'est toujours mieux de faire relire avant de publier, mettez vos collègues à contribution ;)
Article d'annonce
Une fois que la fiche est publiée, on peut écrire l'article d'annonce de la nouveauté (que ce soit une correction, un nouveau service web, ...).
Catégories à cocher: Blog et Blog/Webservices.

Ajouter aussi l'image mise en avant.

Pour une annonce de service web, utilisez l'image Webservices:

C'est elle qui d'un coup d'œil permet de savoir de quoi parle un article du blog, dans la liste anté-chronologique.
Trouvez un titre pas trop long, et soyez conscient que le premier paragraphe de l'article sera aussi présent dans la fameuse liste des articles.

L'article doit expliquer la raison de la modification annoncée (si c'est un nouveau service, ce qu'il est censé faire, si c'est une amélioration, ce qui n'allait pas et comment ça a été résolu).
Il ne faut pas oublier de faire référence à la fiche du service (et de mettre un lien).
D'ailleurs, une fois que cet article est publié, il faut l'ajouter aux références de la fiche.
Faire le ménage
Il s'agit ensuite de supprimer (ou d'arrêter) l'éventuelle instance précédente.
Au plus, on laissera deux instances de même nom (mais de version différente) sur la machine de production:
- éteindre la version précédente (ex:
-3) - supprimer la version d'encore avant (ex:
-2)
pour ne plus laisser en route que la dernière version (ex: -4).