 GitBucket
GitBucket
Apprentissage du RNSR avec répartition géographique - essai avec DVC
|
|
|||
|---|---|---|---|
| .dvc | 3 years ago | ||
| .vscode | 3 years ago | ||
| bin | 3 years ago | ||
| data | 3 years ago | ||
| dvc_plots | 3 years ago | ||
| libs | 3 years ago | ||
| .dvcignore | 3 years ago | ||
| .gitignore | 3 years ago | ||
| README.md | 3 years ago | ||
| dvc.lock | 3 years ago | ||
| dvc.yaml | 3 years ago | ||
| metrics.json | 3 years ago | ||
| metrics.tsv | 3 years ago | ||
| package-lock.json | 3 years ago | ||
| package.json | 3 years ago | ||
| params.yaml | 3 years ago | ||
| plots_diff.png | 3 years ago | ||
| precision.json | 3 years ago | ||
| precision.tsv | 3 years ago | ||
{kind=link}
rnsr-geo-ml-dvc
Apprentissage du RNSR avec répartition géographique - essai avec DVC.
Voir les travaux précédents: https://gitbucket.inist.fr/parmentf/rnsr-ml.
DVC
Initialisation
La documentation de l'extension DVC de VSCode dit que pour initialiser le dépôt il faut taper dvc exp init -i, mais ça ne marche pas avec ma version de DVC (qui est apparemment plus récente que ce à quoi s'attend l'extension).
$ dvc init Initialized DVC repository. You can now commit the changes to git. +---------------------------------------------------------------------+ | | | DVC has enabled anonymous aggregate usage analytics. | | Read the analytics documentation (and how to opt-out) here: | | <https://dvc.org/doc/user-guide/analytics> | | | +---------------------------------------------------------------------+ What's next? ------------ - Check out the documentation: <https://dvc.org/doc> - Get help and share ideas: <https://dvc.org/chat> - Star us on GitHub: <https://github.com/iterative/dvc>
Cette commande a créé:
.dvcignore.dvc.gitignoreconfig
Alors que l'installation de l'extension VSCode a ajouté:
.vscodesettings.json
Pour créer un remote, je tape dvc remote add -d local /home/parmentf/data/dvc.
Il faut juste que le répertoire existe (et soit vide ou déjà consacré à ça).
Ajout de fichier
$ dvc add data/netscity-ville-aire-uniq.tsv
100% Adding...|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████|1/1 [00:00, 20.28file/s]
To track the changes with git, run:
git add data/netscity-ville-aire-uniq.tsv.dvc data/.gitignore
To enable auto staging, run:
dvc config core.autostage true
Donc, si on veut se simplifier la vie sur les ajouts suivants:
dvc config core.autostage true
Stages
Pour lancer un pipeline en dehors d'une expérience (composé de plusieurs stages), il suffit de faire dvc repro.
Les fichiers résultats outs d'un stage (une étape) sont automatiquement ajoutés à DVC.
Plots
Même sans expérience, on peut comparer des... runs: après un dvc repro, on peut faire (à condition d'avoir configuré des plots et des metrics) dvc metrics diff, ou dvc plots diff.
$ dvc metrics diff Path Metric HEAD workspace Change metrics.json max 0.76 0.828 0.068 metrics.json mean 0.28285 0.25927 -0.02358 metrics.json median 0.2155 0.21 -0.0055 metrics.json min 0.0356 0.0674 0.0318
Le résultat d'un premier dvc plots diff (sur les 48 aires géographiques):
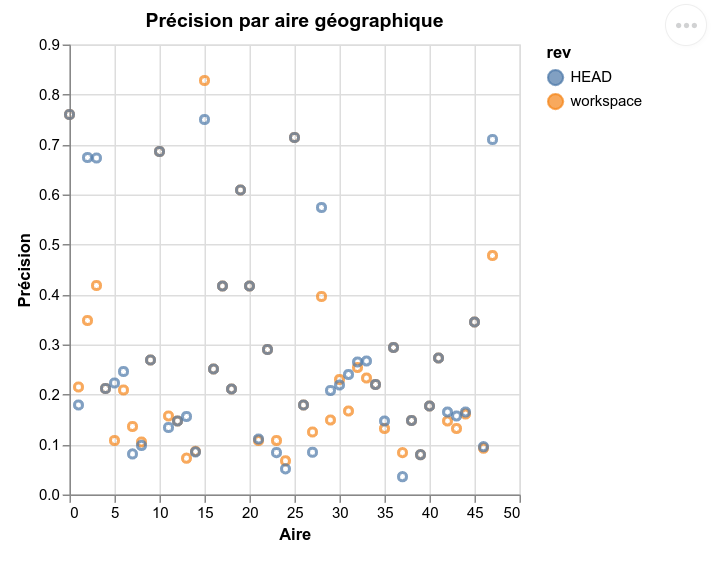
C'est une page HTML située dans le répertoire dvc_plots.
Diagram
dvc dag --mermaid (ou dvc dag --md) permet de visualiser ça (dans VSCode, il y a l'extension Markdown Preview Mermaid Support):
flowchart TD
node1["data/addresses-40-cnrs-rnsr-big-classes-test.txt.dvc"]
node2["data/addresses-40-cnrs-rnsr-big-classes-train.txt.dvc"]
node3["data/netscity-ville-aire-uniq.tsv.dvc"]
node4["evaluate"]
node5["extract-areas@test"]
node6["extract-areas@train"]
node7["prepare@test"]
node8["prepare@train"]
node9["split"]
node10["train"]
node1-->node7
node2-->node8
node3-->node7
node3-->node8
node5-->node10
node6-->node9
node6-->node10
node7-->node5
node7-->node9
node8-->node6
node8-->node9
node9-->node10
node10-->node4
Et avec dvc dag --outs --md:
flowchart TD
node1["areas"]
node2["data/addresses-40-cnrs-rnsr-big-classes-test.txt"]
node3["data/addresses-40-cnrs-rnsr-big-classes-train.txt"]
node4["data/area-address-test.tsv"]
node5["data/area-address-train.tsv"]
node6["data/areas-test.txt"]
node7["data/areas-train.txt"]
node8["data/netscity-ville-aire-uniq.tsv"]
node9["metrics.json"]
node10["models"]
node11["precision.json"]
node1-->node10
node2-->node4
node3-->node5
node4-->node1
node4-->node6
node5-->node1
node5-->node7
node6-->node10
node7-->node1
node7-->node10
node8-->node4
node8-->node5
node10-->node9
node10-->node11
Note: DAG signifie Directed Acyclic Graph (ou Graphe Orienté Acyclique).
Aires géographiques
Le split donne 100 aires géographiques, dont plus de 50 avec moins de 40 adresses.
On les rassemble donc dans areas/GatheredLittleAreas, ce qui laisse 48 aires (dont celle-ci) avec au moins 40 (inclus) aires.
Experiments
Les experiments sont un moyen de nommer et de retrouver des exécutions du pipeline.
On en crée une en lançant dvc exp run.
$ dvc exp run
'data/addresses-40-cnrs-rnsr-big-classes-train.txt.dvc' didn't change, skipping
'data/netscity-ville-aire-uniq.tsv.dvc' didn't change, skipping
Stage 'prepare@train' didn't change, skipping
Stage 'extract-areas@train' didn't change, skipping
'data/addresses-40-cnrs-rnsr-big-classes-test.txt.dvc' didn't change, skipping
Stage 'prepare@test' didn't change, skipping
Stage 'split' didn't change, skipping
Stage 'extract-areas@test' didn't change, skipping
Stage 'train' didn't change, skipping
Stage 'evaluate' didn't change, skipping
Reproduced experiment(s): exp-44136
Experiment results have been applied to your workspace.
To promote an experiment to a Git branch run:
dvc exp branch <exp> <branch>