 GitBucket
GitBucket
Les web services de l'Inist
|
|
|||
|---|---|---|---|
| .vscode | 1 year ago | ||
| address-kit | 1 year ago | ||
| affiliation-rnsr | 1 year ago | ||
| affiliations-tools | 1 year ago | ||
| ark-tools | 1 year ago | ||
| astro-ner | 1 year ago | ||
| authors-tools | 1 year ago | ||
| base-line | 1 year ago | ||
| base-line-nodejs | 3 years ago | ||
| base-line-python | 3 years ago | ||
| biblio-ref | 1 year ago | ||
| biblio-tools | 1 year ago | ||
| bin | 2 years ago | ||
| chem-ner | 1 year ago | ||
| co-deduplicate | 1 year ago | ||
| data-computer | 1 year ago | ||
| data-rapido | 1 year ago | ||
| data-termsuite | 1 year ago | ||
| data-thesesul | 1 year ago | ||
| data-topcitation | 1 year ago | ||
| data-workflow | 1 year ago | ||
| data-wrapper | 1 year ago | ||
| diseases-ner | 1 year ago | ||
| domains-classifier | 1 year ago | ||
| funder-ner | 1 year ago | ||
| hal-classifier | 1 year ago | ||
| images | 2 years ago | ||
| irc3-species | 1 year ago | ||
| kos2vec | 2 years ago | ||
| loterre-resolvers | 1 year ago | ||
| loterre-xslt/ v1 | 4 years ago | ||
| mapping-tools | 1 year ago | ||
| ner-tagger | 1 year ago | ||
| nlp-tools | 2 years ago | ||
| nlp-tools2 | 1 year ago | ||
| pdf-text | 1 year ago | ||
| pdf-tools | 1 year ago | ||
| person-ner | 1 year ago | ||
| sciencemetrix-classification | 1 year ago | ||
| terms-extraction | 1 year ago | ||
| terms-tools | 1 year ago | ||
| text-clustering | 1 year ago | ||
| www-home | 2 years ago | ||
| .gitignore | 2 years ago | ||
| .npmignore | 4 years ago | ||
| .npmrc | 4 years ago | ||
| CHANGELOG.md | 4 years ago | ||
| CONTRIBUTING.md | 2 years ago | ||
| Makefile | 2 years ago | ||
| README.md | 2 years ago | ||
| docker-compose.yml | 3 years ago | ||
| package.json | 2 years ago | ||
Les web services TDM de l'Inist
Web services en Python
Créer un web service en Python consiste à créer un script Python capable de traiter un fichier JSON fourni via l'entrée standard (sdtin) et de produire un fichier JSON similaire dans la sortie standard (stdout).
Exemple de fichier python
#!/usr/bin/python3
import sys
import json
for line in sys.stdin:
data = json.loads(line)
data['value'] = data['value'].upper() # YOUR STATEMENT HERE
sys.stdout.write(json.dumps(data))
sys.stdout.write('\n')
Pour transformer un programme Python en web service, il est nécessaire de déclarer un point d’entrée (entrypoint) via la création d’un fichier .ini dans une arborescence spécifique (cf . Convention de nommage).
Ce fichier contiendra la documentation au format OpenAPI, et une référence au fichier python a exécuter.
NB : Pensez à vérifier les permissions d'éxecution du fichier python. Pour rendre un fichier python éxecutable : chmod +x nom-du-fichier.py
Exemple de fichier .ini
# OpenAPI Documentation - JSON format (dot notation)
mimeType = application/json
post.responses.default.description = Return all objects with enrich fields
post.responses.default.content.application/json.schema.$ref = #/components/schemas/JSONStream
post.summary = Enrich one field of each Object with a Python function
post.requestBody.required = true
post.requestBody.content.application/json.schema.$ref = #/components/schemas/JSONStream
post.parameters.0.in = query
post.parameters.0.in = query
post.parameters.0.name = indent
post.parameters.0.schema.type = boolean
post.parameters.0.description = Indent or not the JSON Result
[use]
plugin = @ezs/local
plugin = @ezs/basics
plugin = @ezs/storage
plugin = @ezs/analytics
[JSONParse]
separator = *
[expand]
path = value
size = 100
[expand/exec]
# command should be executable !
# Use absolute path
command = ./v1/strings/uppercase.py
[dump]
indent = env('indent', false)
L'installation de paquet Python spécifique est possible en déclarant les paquets à installer à la racine de son web service dans un ficher requirements.txt.
Exemple de fichier requirements.txt
spacy==2.3.5 pytextrank==2.0.1 pycld3 en-core-web-sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.3.1/en_core_web_sm-2.3.1.tar.gz fr-core-news-sm @ https://github.com/explosion/spacy-models/releases/download/fr_core_news_sm-2.3.0/fr_core_news_sm-2.3.0.tar.gz
Développer
Il est possible de tester localement (sur son poste) son webservice, dans un environnement identique à celui de production, pour cela :
en Python
Avec Docker:
make python ./mon_repertoire
Attention, les propriétaires des fichiers peuvent changer, il faut utiliser
make resetaprès avoir arrêté le serveur, pour récupérer un état de git stable.
Alternative: lancer le serveur ezs directement, avec votre user. C'est plus rapide et léger, mais nécessite d'avoir installé vos paquets:
- paquets python: dans un environnement virtuel, actif
- paquets node: un
npm installà la racine du dépôt devrait suffire.
Ensuite:
cd base-line-python && npx ezs -m -v -d .
en NodeJS
Avec Docker:
make nodejs ./base-line
Avec node (il faut d'abord avoir lancé npm install à la racine du dépôt):
cd base-line && npx ezs -m -v -d .
Ensuite, le webservice est accessible à cette adresse http://localhost:31976.
WARNING: Docker modifie le propriétaire des fichiers. Pour restaurer les permissions:
make reset
Tester
Des exemples de requêtes sont disponibles dans des fichers examples.http.
Ceux-ci peuvent être utilisés directement dans VSCode, avec l'extension REST Client (humao.rest-client).
Ils peuvent également être lancés en ligne de commande via rest-cli ou via dot-http.
Exemple 1 : lancement des exemples sans affichage
$ npx restcli ./biblio-tools/examples.http examples:1 [1] POST https://biblio-tools.services.inist.fr/v1/unpaywall/is_oa?indent=true examples:2 [1] POST https://biblio-tools.services.inist.fr/v1/crossref/prefixes/expand?indent=true
Exemple 2 : lancement des exemples avec affichage
$ npx restcli --full ./affiliations-libpostal/examples.http
examples:1 [1] POST https://affiliations-libpostal.services.inist.fr/v1/parse?indent=true
POST https://affiliations-libpostal.services.inist.fr/v1/parse?indent=true
Content-Type: application/json
[
{
"value": "Barboncino 781 Franklin Ave, Crown Heights, Brooklyn, NY 11238"
}
]
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Connection: close
Content-Disposition: inline
Content-Encoding: gzip
Content-Type: application/octet-stream
Date: Fri, 23 Jul 2021 09:00:14 GMT
Server: nginx/1.15.10
Transfer-Encoding: chunked
[{
"value": {
"id": "Barboncino 781 Franklin Ave, Crown Heights, Brooklyn, NY 11238",
"value": {
"house": "barboncino",
"house_number": "781",
"road": "franklin ave",
"suburb": "crown heights",
"city_district": "brooklyn",
"state": "ny",
"postcode": "11238"
}
}
}]
Documenter
Documentation OpenAPI
Chaque service, chaque route, doit être documenté en respectant la norme OpenAPI 3.0 (swagger).
La documentation de chaque route doit être placée dans le fichier .ini correspondant à sa route API.
Pour placer la document openapi dans les fichiers .ini, la syntaxe Swagger au format JSON doit être convertie au format "dot notation"
Chaque fichier .ini doit contenir les champs de métadonnées suivant:
mimeType: dont la valeur la plus courante estapplication/jsonpost.operationId: formée sur le modèle de la route (ou du chemin du fichier.inidepuis la racine de l'instance)post.summary: la description courte du service (celle qui apparaîtra en premier dans OpenAPI)post.description: la description longue du service (idéalement, elle contient des explications détaillées, celles que l'on mettait auparavant dans le README de l'instance), au format Markdown (attention, tout doit rester sur la même ligne; pour insérer un passage à la ligne souvent nécessaire en Markdown, utiliser les caractères^M).
Exemple :
Cette partie de métadonnées
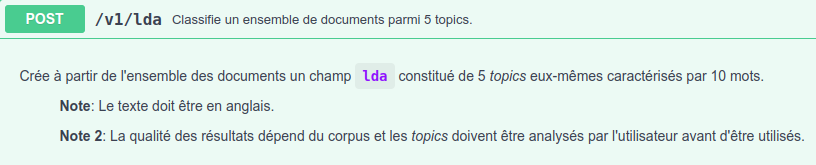
# Entrypoint output format mimeType = application/json # OpenAPI Documentation - JSON format (dot notation) post.operationId = post-v1-lda post.summary = Classifie un ensemble de documents parmi 5 topics. post.description = Crée à partir de l'ensemble des documents un champ `lda` constitué de 5 _topics_ eux-mêmes caractérisés par 10 mots.^M> **Note**: Le texte doit être en anglais.^M^M> **Note 2**: La qualité des résultats dépend du corpus et les _topics_ doivent être analysés par l'utilisateur avant d'être utilisés. post.tags.0 = data-computer post.requestBody.required = true
donnera dans l'OpenAPI:
Tags
Si vous souhaitez enrichir la documentation par défaut, en ajoutant des tags, des components, il est possible d'ajouter un fichier standard swagger.json à la racine de votre instance.
Le serveur prendra en compte tout le fichier SAUF ce qui correspond aux informations concernant les routes (qui doivent être placées dans le fichier .ini).
Exemples
Il est très important de mettre des exemples dans la documentation OpenAPI.
Malheureusement, la syntaxe utilisée (notation pointée) pour ce faire dans les .ini est très rébarbative.
Mais on peut utiliser un fichier examples.http placé à la racine d'une instance et la cible make example-metadata pour générer ces exemples: il exécute une requête du fichier examples.http et fournit les lignes en notation pointée pour la requête et la réponse de l'exemple.
Exemple:
$ make example-metadata mapping-tools 0 post.requestBody.content.application/json.example.0.id: 1 post.requestBody.content.application/json.example.0.value: 200919362L post.requestBody.content.application/json.example.1.id: 2 post.requestBody.content.application/json.example.1.value: 200112440X post.responses.default.content.application/json.example.0.id: 1 post.responses.default.content.application/json.example.0.value: INEE post.responses.default.content.application/json.example.1.id: 2 post.responses.default.content.application/json.example.1.value: INS2I
Il suffit ensuite de copier-coller ces lignes en haut du .ini, à la fin des métadonnées. Prenez quand même garde à ne pas mettre plusieurs example.0 (il existe une autre syntaxe pour mettre plusieurs exemples).
Note: pour que ce script fonctionne, il faut que node 14+ soit installé, et que la commande
npm installait été lancée à partir de la racine du dépôt.Note 2: préférez plusieurs valeurs dans le tableau de l'exemple, pour éviter que le script ne fasse abstraction du tableau (auquel cas il faudrait l'ajouter à la main dans les exemples).
Note 3: vous pouvez nommer les exemples, en ajoutant
# @name identifiantsur une ligne avant la requête (en remplaçant identifiant par une valeur unique).
Ainsi vous pouvez appeler la commandemake example-metadata terms-extraction v1TeeftWithNumbersEn.
Déclarer la documentation Swagger
Le répertoire www-home contient le HTML de la page de documentation OpenAPI https://openapi.services.inist.fr.
Obsolète: Pour ajouter une instance dans le menu déroulant (en haut à droite), il vous suffit de la déclarer dans www-home/index.html pour qu'elle soit prise en compte.
📗 Pour tester le rendu de vos métadonnées dans OpenAPI, lancez votre instance en local, puis utilisez l'instance de la machine d'intégration
www-home, et sélectionnezlocalhost
Cela se fait maintenant automatiquement au make publish (mais il faut avoir les accès à la machine daf pour ça).
Voir Publication d'une instance.
Convention de nommage
Chaque instance sur l'ezmaster de la machine aura un nom en trois parties:
- texte (domaine)
- texte (spécialité)
- numéro (version)
La troisième partie du champ ne doit pas être communiquée à l'extérieur, c'est un numéro de version (si plusieurs instances ont les mêmes deux premiers champs, c'est la dernière version qui est exposée quand on n'utilise pas de numéro de version, ce qui sera le cas).
Le numéro de version permet la mise à jour de l'image docker associée au webservice.
Nom de l'instance
Les champs textuels sont obligatoirement en minuscules, et sans accent (mais peuvent contenir des chiffres) et donc de préférence en anglais. Ils ne doivent pas contenir un nom de personne.
La première partie décrit le domaine d'application du webservice. Exemple : affiliation, text, classification, nlp, etc.
La seconde partie décrit une spécialité du domaine. Cette spécificité est principalement liée à une image docker différente, comme c'est le cas si les différents web services d'un domaine utilisent des langages différents (C++, python, nodejs, etc.).
Nom des répertoires
Chaque instance donne accès à une arborescence de webservices.
Le nom de route dépend du nom des répertoires.
Les noms des répertoires doivent donc être choisis dans cette optique.
Il convient donc de respecter les pratiques communément admises dans la définition d'API de type REST.
En utilisant des noms de répertoires en minuscules, sans accent (mais pouvant contenir des chiffres) et de préférence en anglais.
Si le premier niveau caractérise obligatoirement la version, les suivants peuvent être adaptés selon le besoin.
On veillera à créer un répertoire si et seulement si il propose plusieurs sous-répertoire ou fichiers.
Plus le chemin est court, mieux c'est.
- Version des APIs (v1, v2, v3, etc.)
- Nom de l'algorithme ou de la ressource utilisés ou de la langue
- Nom de l'action ou de l'algorithme caractérisant le traitement
- (...)
Exemples :
/v1/test/analyse/v2/istex/expand/v1/en/stemmer/analyse/v1/teeft/fr
Fichier d'exemple
Chaque répertoire dédié à une instance contiendra au moins un fichier examples.http.
Ce fichier permet d'exécuter rapidement et simplement des exemples simples d'utilisation des webservices à travers VSCode ou restcli (en ligne de commande).
Le format du fichier est celui précisé dans la documentation vscode https://github.com/Huachao/vscode-restclient#usage.
Voir aussi Tester.
Fichier de test
Quand l'instance est déployée et publiée, on peut générer un fichier tests.hurl à partir d'un fichier examples.http.
Il y a une commande make generate-example-tests address-kit.
Pour lancer le fichier, à condition d'avoir installé les paquets npm:
$ npx hurl --test address-kit/tests.hurl ./address-kit/tests.hurl: Running [1/1] ./address-kit/tests.hurl: Success (2 request(s) in 8858 ms) -------------------------------------------------------------------------------- Executed files: 1 Succeeded files: 1 (100.0%) Failed files: 0 (0.0%) Duration: 8860 ms
Créer une version
Afin de faciliter le déploiement (et de le limiter à un répertoire), on peut utiliser les helpers du Makefile (make version-major, make version-minor, make version-patch).
Ils se chargent de mettre un tag git sur répertoire et de le pousser sur le dépôt. Leur seul paramètre est le nom du répertoire.
Exemple:
$ make version-major terms-extraction Décompte des objets: 1, fait. Écriture des objets: 100% (1/1), 185 bytes | 185.00 KiB/s, fait. Total 1 (delta 0), reused 0 (delta 0) remote: Updating references: 100% (1/1) To ssh://gitbucket.inist.fr:22222/tdm/web-services.git * [new tag] terms-extraction@1.0.0 -> terms-extraction@1.0.0 Nouvelle version créée: terms-extraction@1.0.0 URL à utiliser: https://gitbucket.inist.fr/tdm/web-services/archive/terms-extraction/terms-extraction@1.0.0.zip
L'URL fournie sert à la configuration de l'instance, et permet la mise à jour du programme.
Publication d'une instance
Pour configurer Prometheus (monitoring interne) et le reverse proxy automatiquement, il faut avoir renseigné le fichier swagger.json dans le répertoire de l'instance et lancé make publish (avec le répertoire comme paramètre).
Ex de swagger.json:
{
"info": {
"title": "ark-tools - Génération des identifiants ARK",
"summary": "Permet la génération d'identifiants ARK uniques et pérennes.",
"version": "1.0.0",
"termsOfService": "https://objectif-tdm.inist.fr/",
"contact": {
"name": "Inist-CNRS",
"url": "https://www.inist.fr/nous-contacter/"
}
},
"servers": [
{
"x-comment": "Will be automatically completed by the ezs server."
},
{
"url": "http://vptdmservices.intra.inist.fr:49194/",
"description": "Latest version for production",
"x-profil": "Standard"
}
],
"tags": [
{
"name": "ark-tools",
"description": "Génération des identifiants ARK",
"externalDocs": {
"description": "Plus de documentation",
"url": "https://gitbucket.inist.fr/tdm/web-services/tree/master/ark-tools"
}
}
]
}
Champs importants: dans servers, champ url.
Lancer avec:
make publish <nom de l'instance>